학기가 마무리되었습니다.
물론 재미는 있었지만 저를 무려 4달동안 괴롭힌 프로젝트가 끝났어요..
우리 되게 잘했거든요? 근데.. 세상이 억까해서..
아니 데모 2시간전에 납땜한거 끊어지는 거 있기없기?
그냥 코드가 에러난거면 어떻게든 고치겠는데.. 정통 3명이 모여서 납땜한거 끊어진거 어떻게 고쳐요..
설상가상으로 3D프린팅도 망해서 뚜껑도 제대로 못열고.. 진짜 생각할 수록 열받네..
그래서 데모도 제대로 못하고 덕분에 우리 프로젝트 되게 잘했는데도 만족스러운 성적이 나오지는 않았습니다..
아 또 생각하니 열받아.. 최소 A+이었는데..
암튼, 그래도 끝이 났으니, 우리 프로젝트를 좀 정리해볼까 하는데요,
이걸 정리하는 이유는 혹시 나중에 누가 우리 아이디어 훔치면 우리꺼라고 주장하기 위해...
사실 뻥이고, 그래도 블로그에 이것저것 많이 올렸는데, 마무리는 해둘까 싶어서 올립니당.😊
우선 결론부터 보여드리자면, 우리 프로젝트 시연 영상입니다.
앞에서 계속 보여드리던 얼굴인식 부분을 보고 싶으시면 대충 5:25쯤 가시면 나올겁니당
저희 전체 source 코드입니다.
https://github.com/PAWSITIVE2024마지막에 급하게 수정한 코드들은 아마 업데이트가 안되어있을텐데...
PAWSITIVE
2024 정보통신공학전공 캡스톤디자인1 PAWSITIVE팀. PAWSITIVE has 4 repositories available. Follow their code on GitHub.
github.com
저는 종강했으니 모르는 일입니다 ㅎㅎㅎ... 아마 에러 수정일텐데.. 뭐, 어차피 또 안쓸건데.. 어차피 아무도 안돌려보실거잖아요 ㅋㅋㅋㅋㅋ
앱
초기 화면
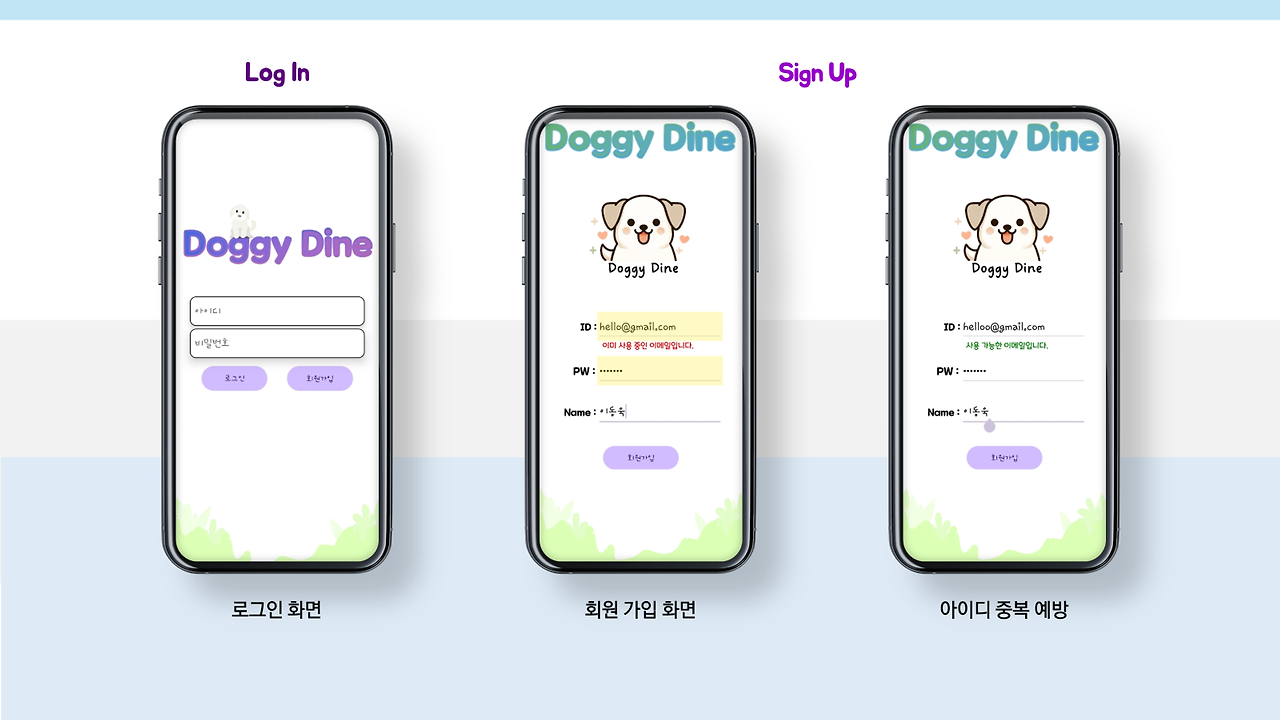
로그인 및 회원가입부터 환경설정까지 입니다.
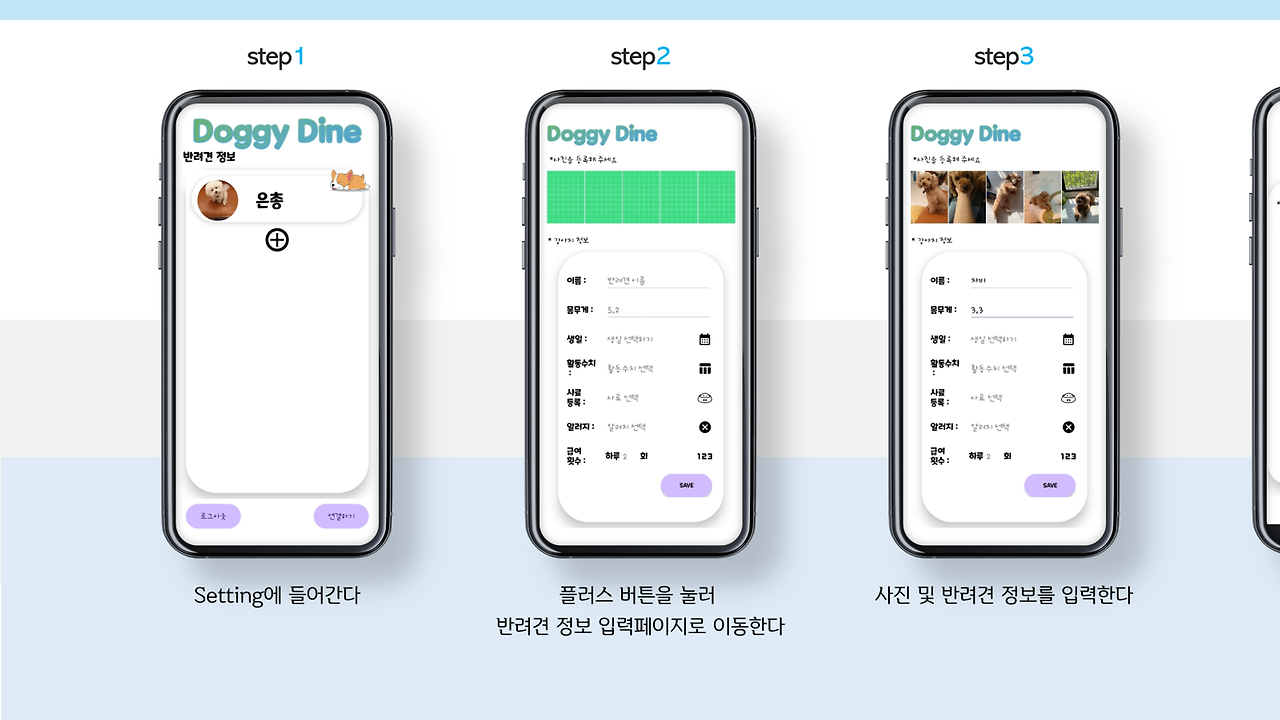
로그인을 하고 환경설정에 들어가면 강아지를 추가할 수 있게 됩니다.
각 강아지에 대한 정보는 사용자의 편리를 고려하여 제작되었고,,, 이런 사용자 편리요소는 대부분 제가 제작하였답니다..후훗.. 물론.. 다 하고 선배님께 데이터 베이스 수정을 떠넘겨버렸죠.. 이제 생각하니 너무 죄송하네요..
갑자기 이렇게 수정하고 있으니 바꿔주세욥! 하면 얼마나 빡칠까.. 우리 선배 알고보니 보살..?
아래에는 연결하기 버튼이랑 로그아웃 버튼이 있는데요 이거는 제가 했답니다 ㅎㅎ.
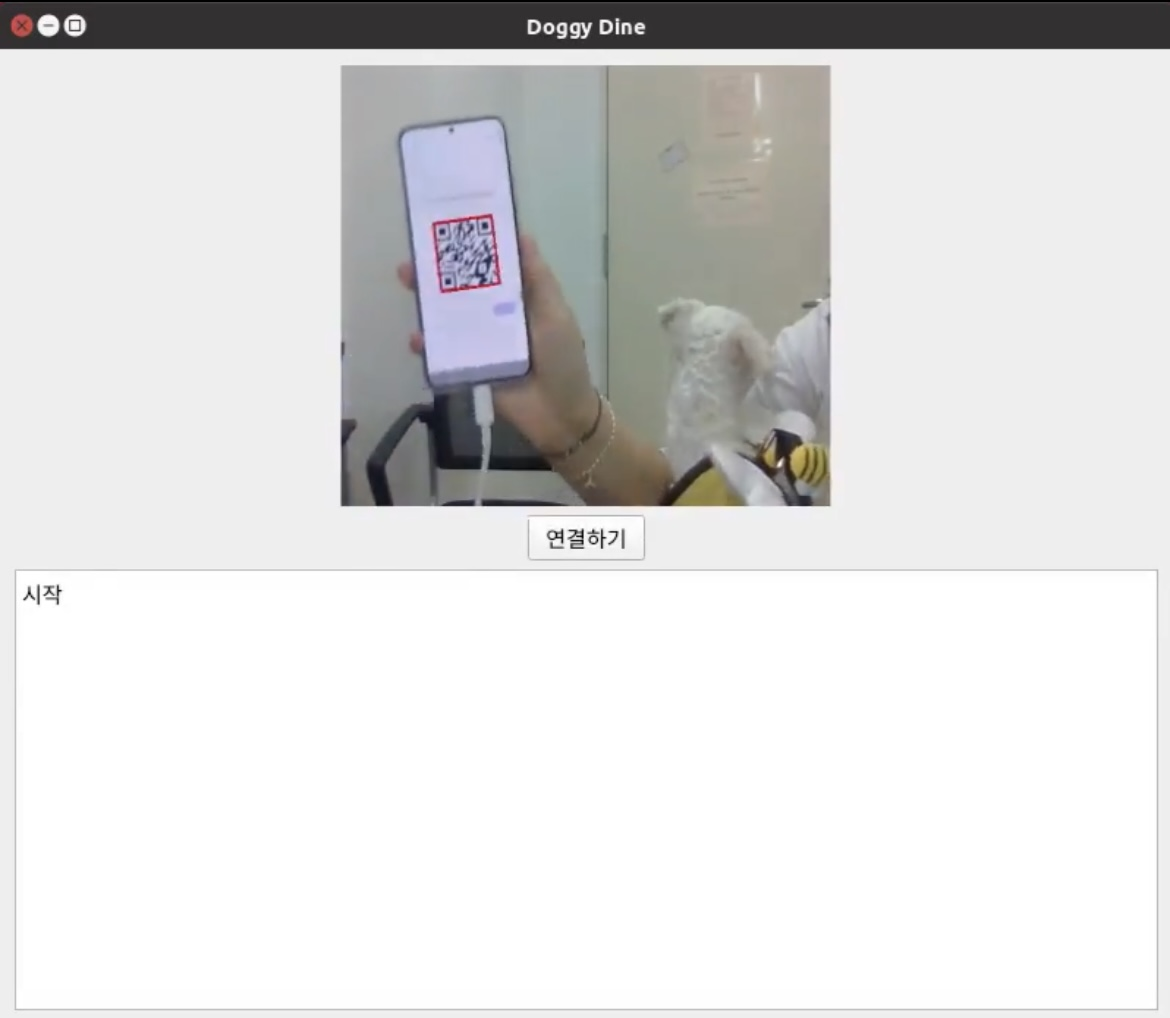
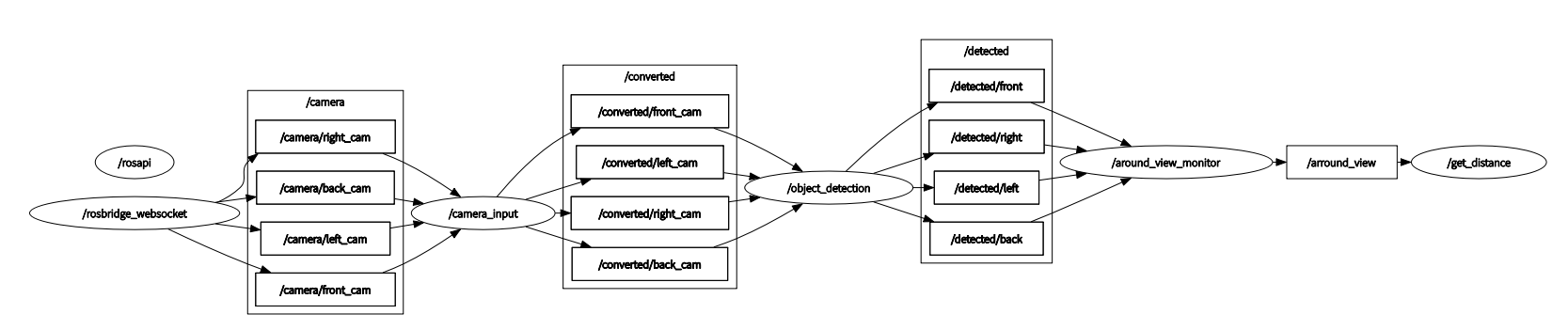
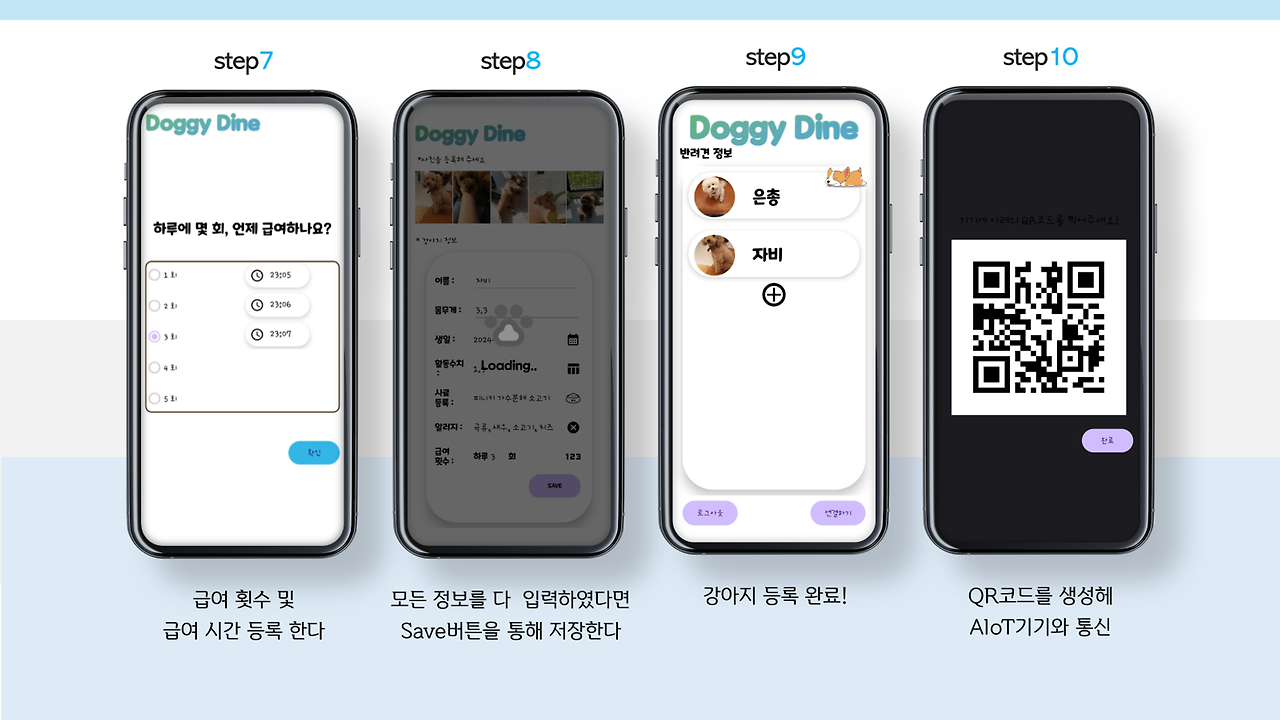
아무래도 저희는 IoT기기이다보니, 기기와 통신을 위해 만들었습니다.
사실 처음에는 WIFI나 Bluetooth를 이용하려고 했는데, 좀.. 잘 안돼서.. 어차피 기기는 사용자가 누군지만 알면 서버에 자동으로 접속해 알아서 작동하도록 설계되어있고, 앞에 카메라도 달려있겠다! User ID를 그냥 QR로 쏴줬습니다.. 근데.. 인식 속도도 빠르고 기능도 잘 되는것 같아서 쾌재를 불렀답니다 ㅎㅎ..

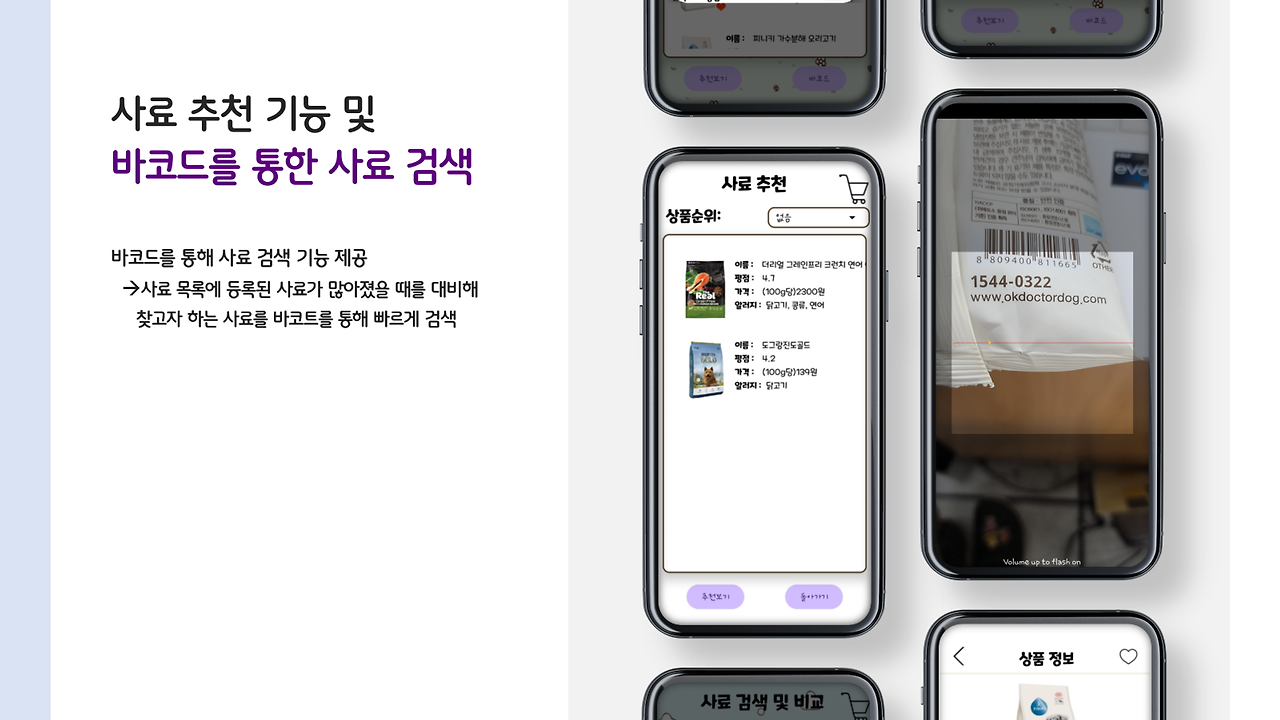
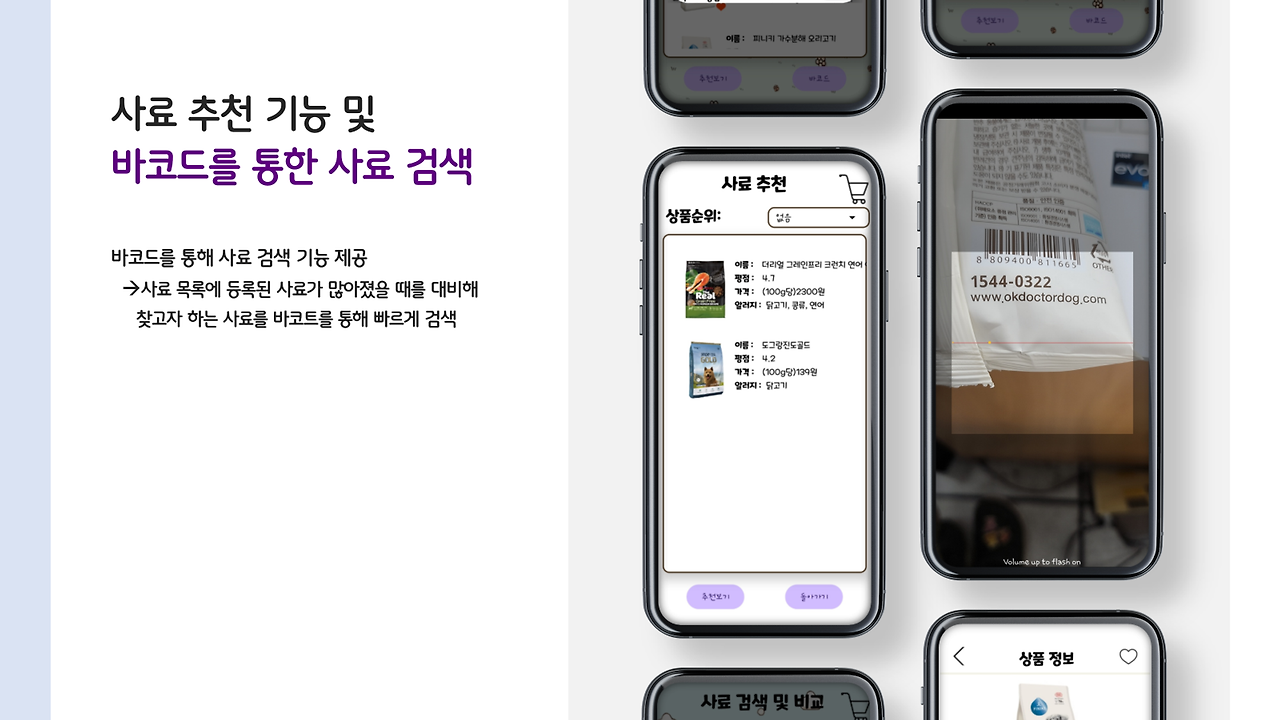
사료 추천 및 비교
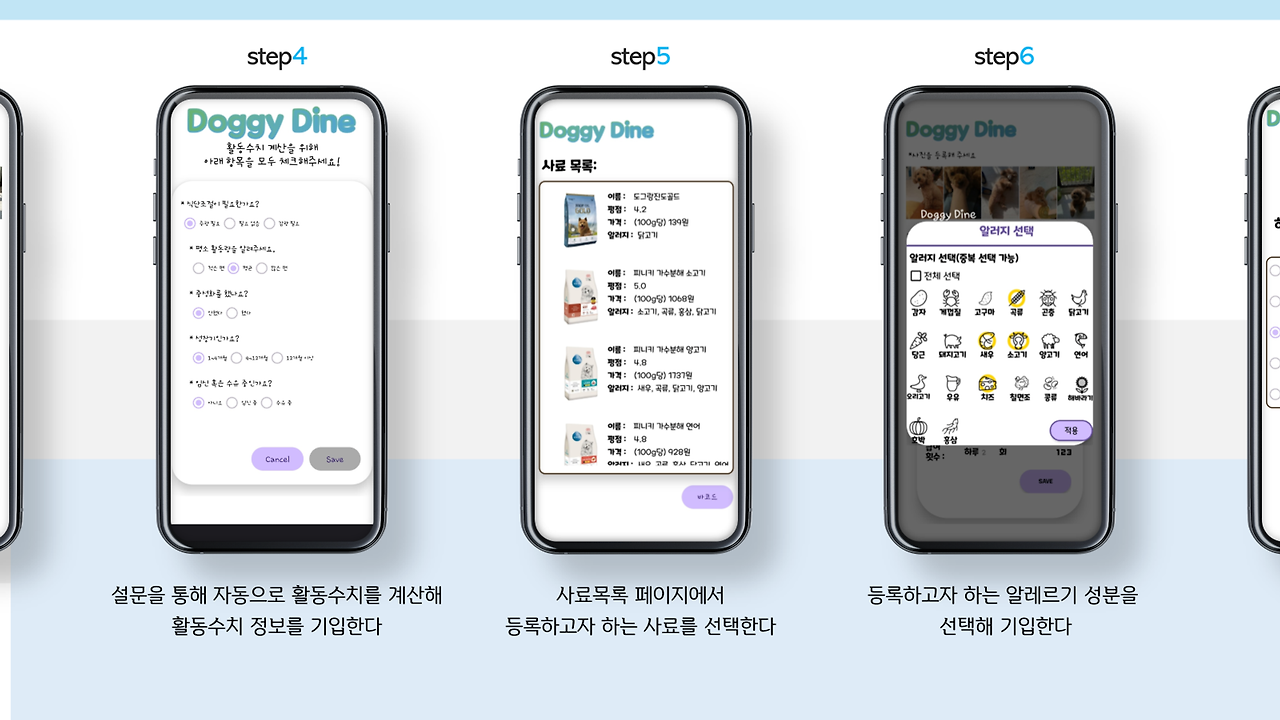
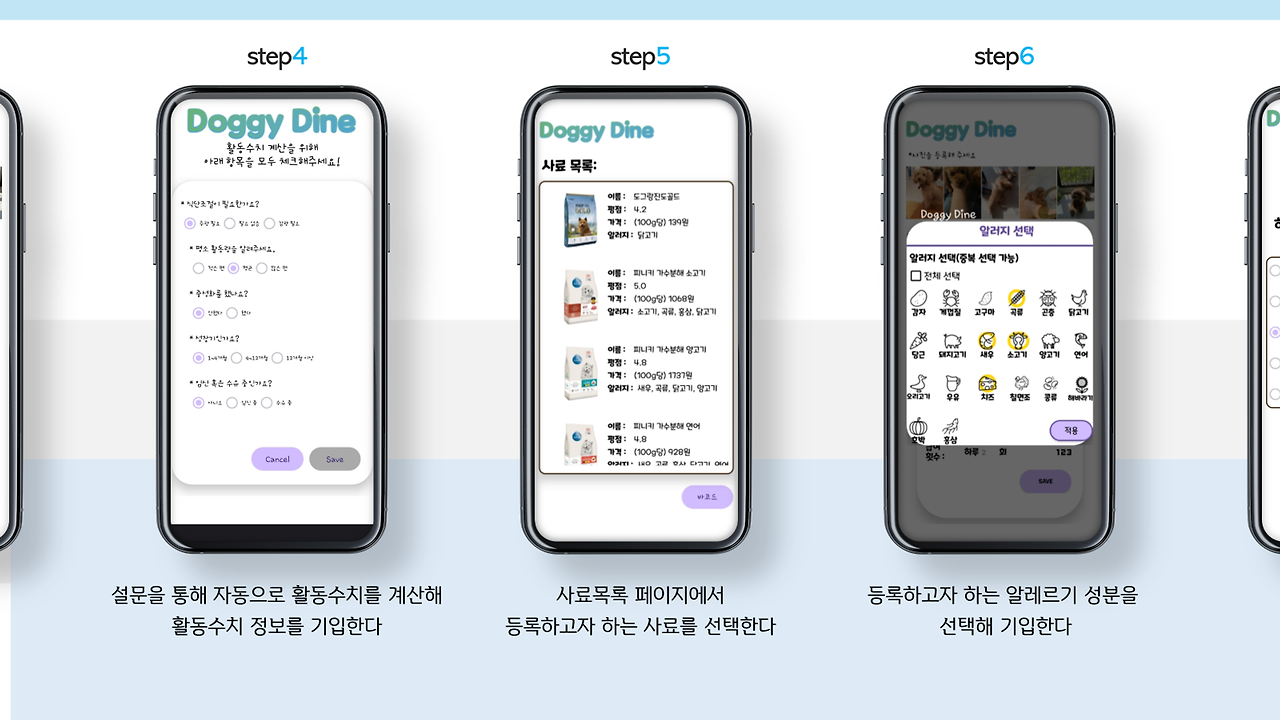
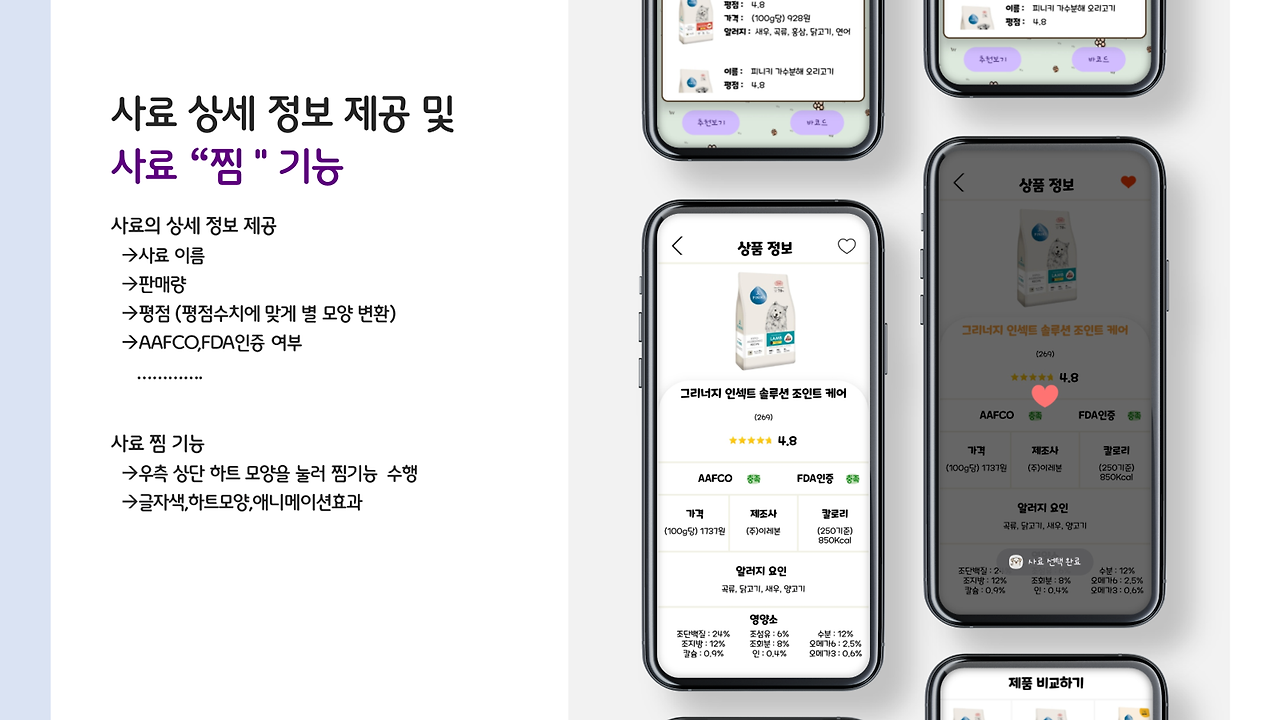
이번엔 저희 앱의 초기 목적!! 사료 비교 및 추천 항목입니당.
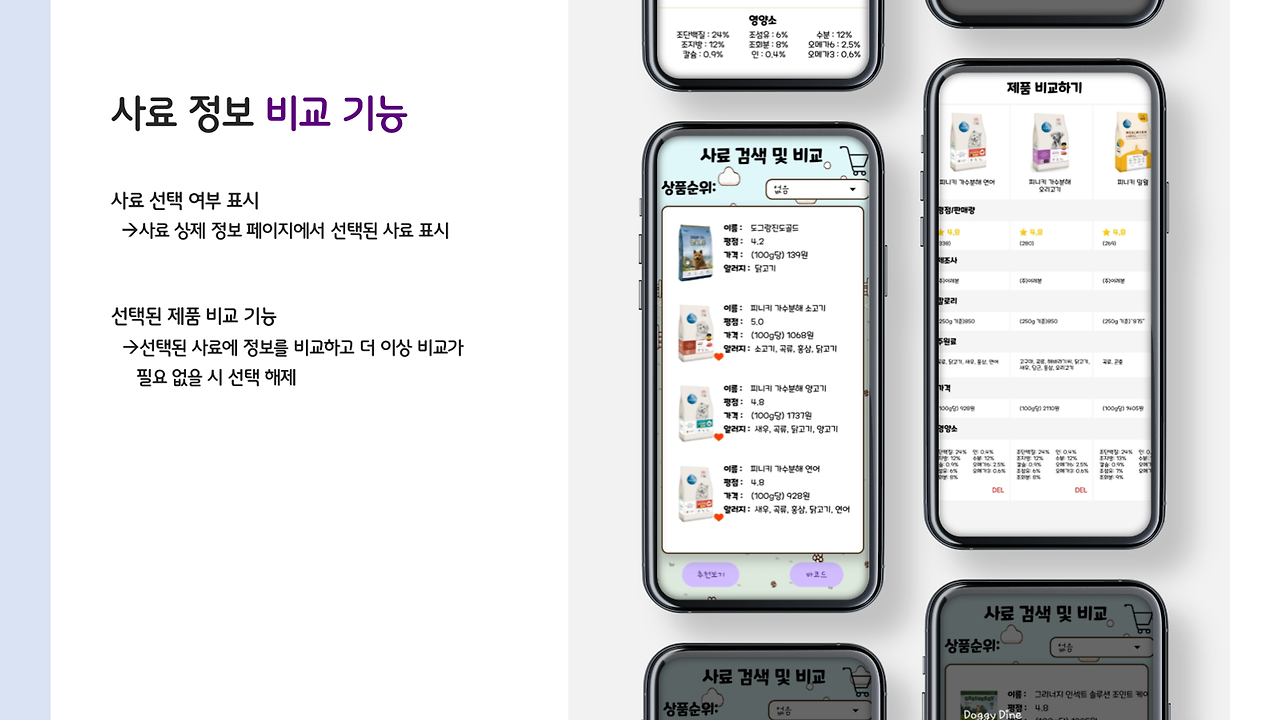
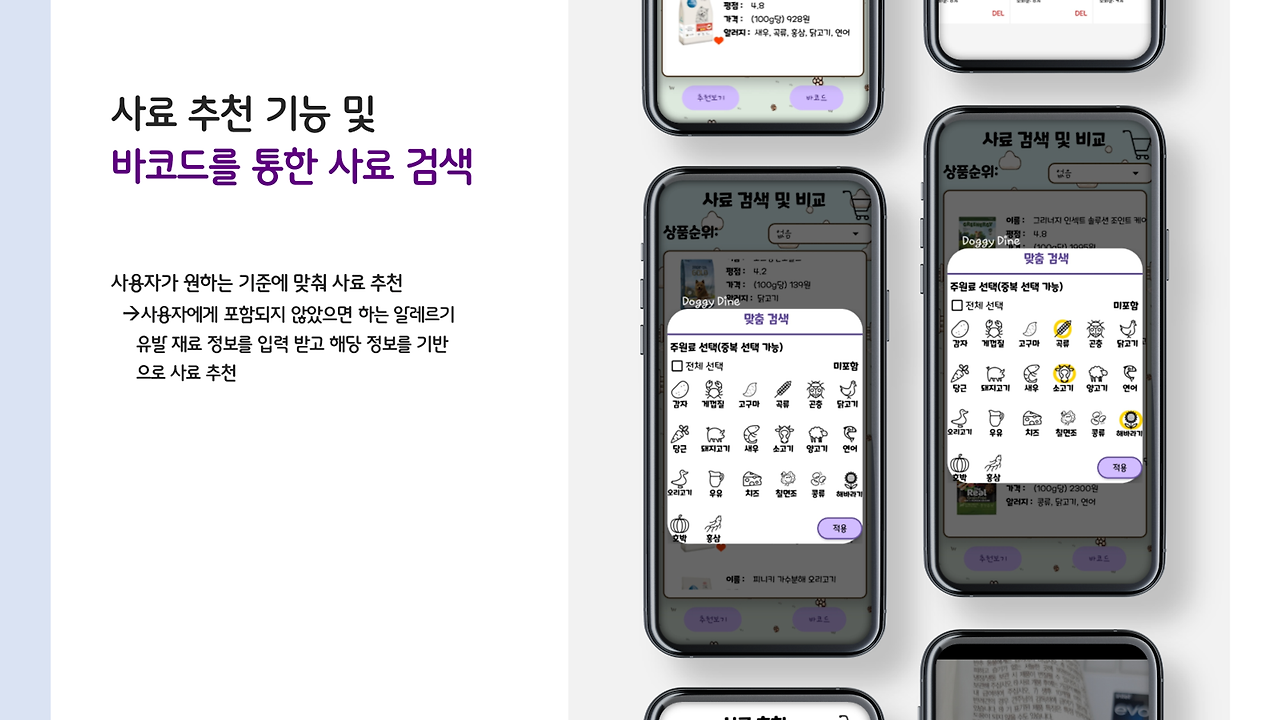
사용자가 바코드를 통해 간편하게 사료 정보를 찾을 수도 있고, 제외해야 하는 알러지 항목을 선택하면, 해당 강아지가 먹어도 되는 사료 리스트가 쭉 나오죠. 사용자는 이 리스트에서 비교를 진행할 수 있답니다!
이부분은 진짜 저희 선배님께서 전적으로 담당해주신 부분으로.. 감사하다는 말씀밖에 못드리겠네요...
저요..? 바코드 읽어오는 것 정도는 제가 했습니다. 깔깔..

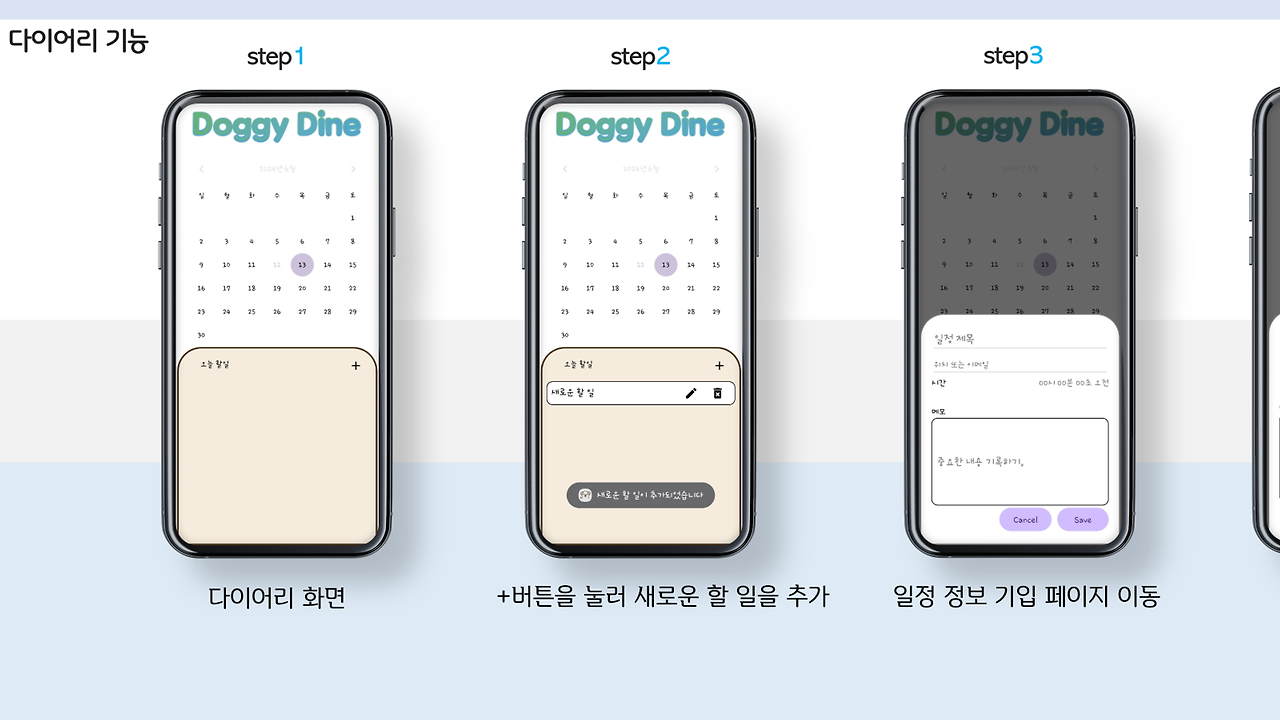
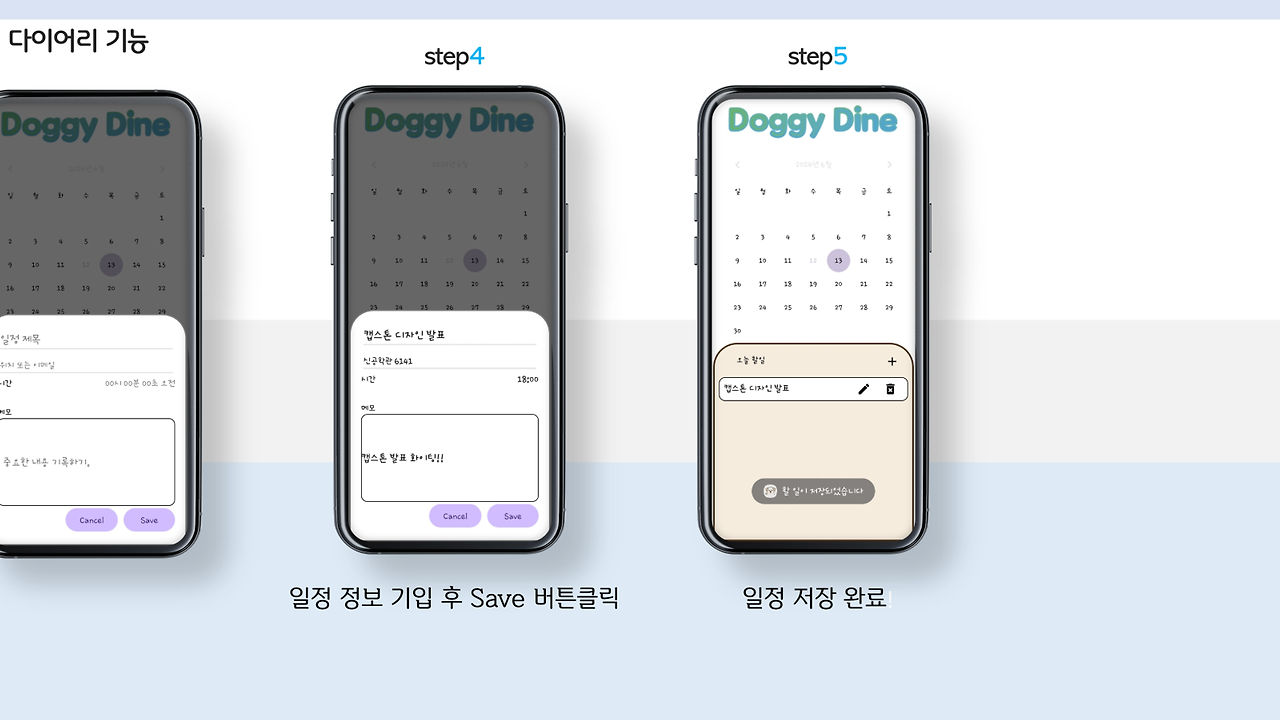
서비스
다음은 서비스 부분입니다!
앱의 재미를 위해 추가한 항목이지요! 다시 말해 없어도 되는 부분이란 소리랍니다!!
이건 제가 했어요.. ㅋㅋㅋㅋㅋ 물론.. 다이어리의 데이터베이스는.. 이 역시 선배님께 떠넘겨버렸답니다..
UI/UX 다 되었으니 연결해 주세욤!!!ㅎㅎㅎ... 죄송하네요..
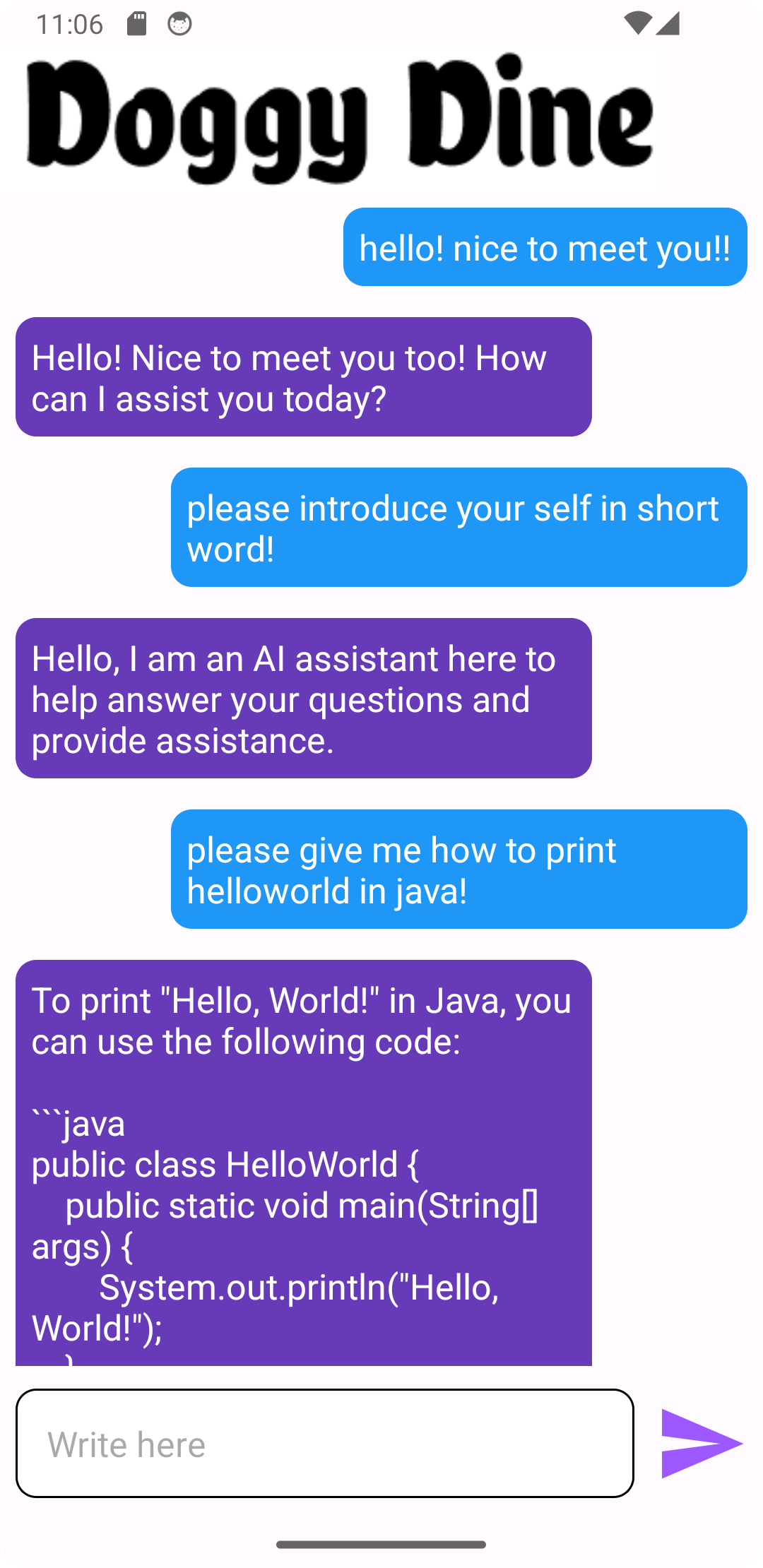
그래도 GPT부분은 프롬프트 엔지니어링까지 제가 100% 완벽히 한겁니다?!?!?
알람같은 부분은 선배님이 데이터베이스에 시간들 저장하고, 가장 빠른 시간 찾을 수 있게 만들어 주신거 가져와서 제가 알람으로 띄우도록 구성 했어욤 ㅎㅎ..




딥러닝
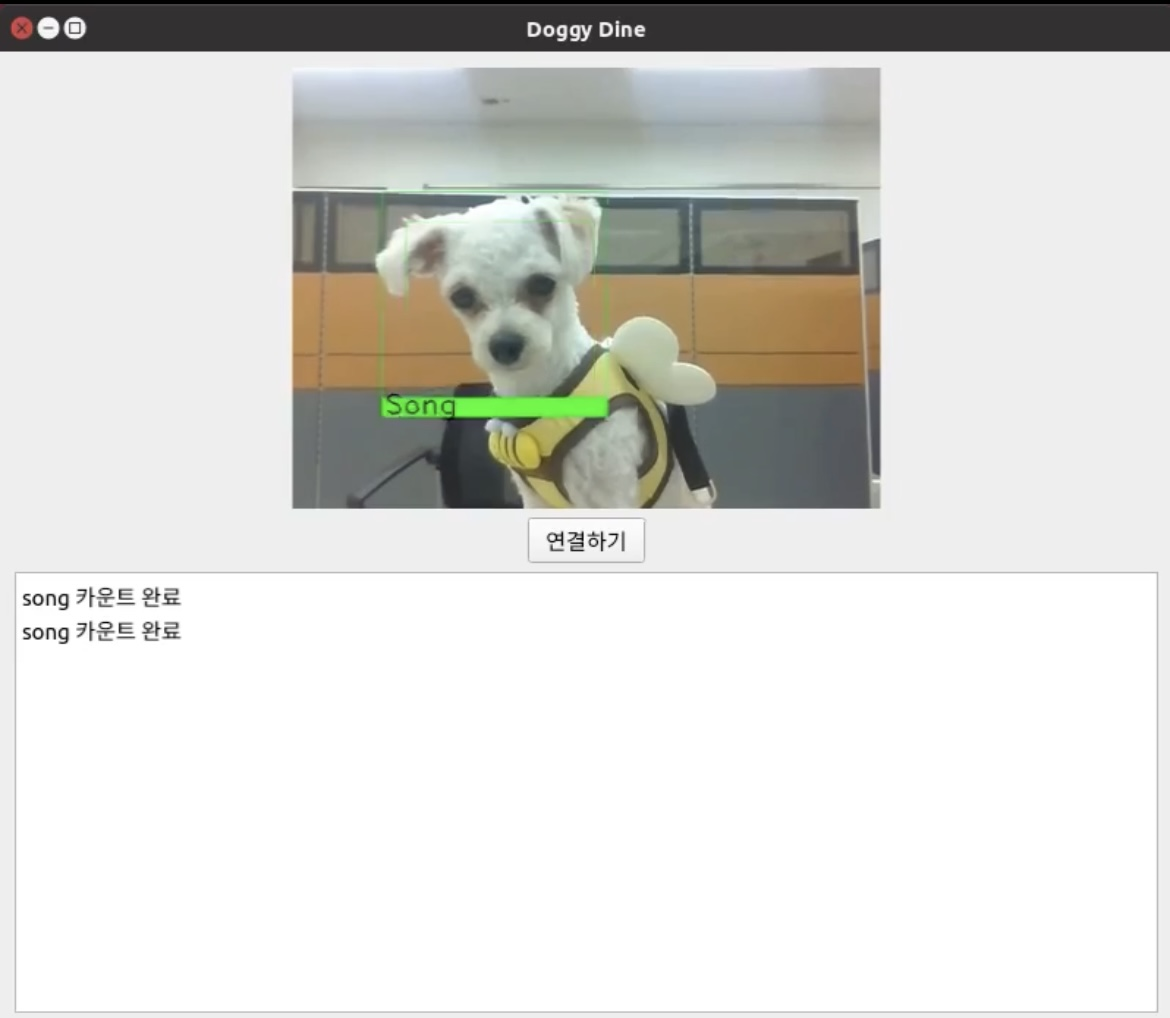
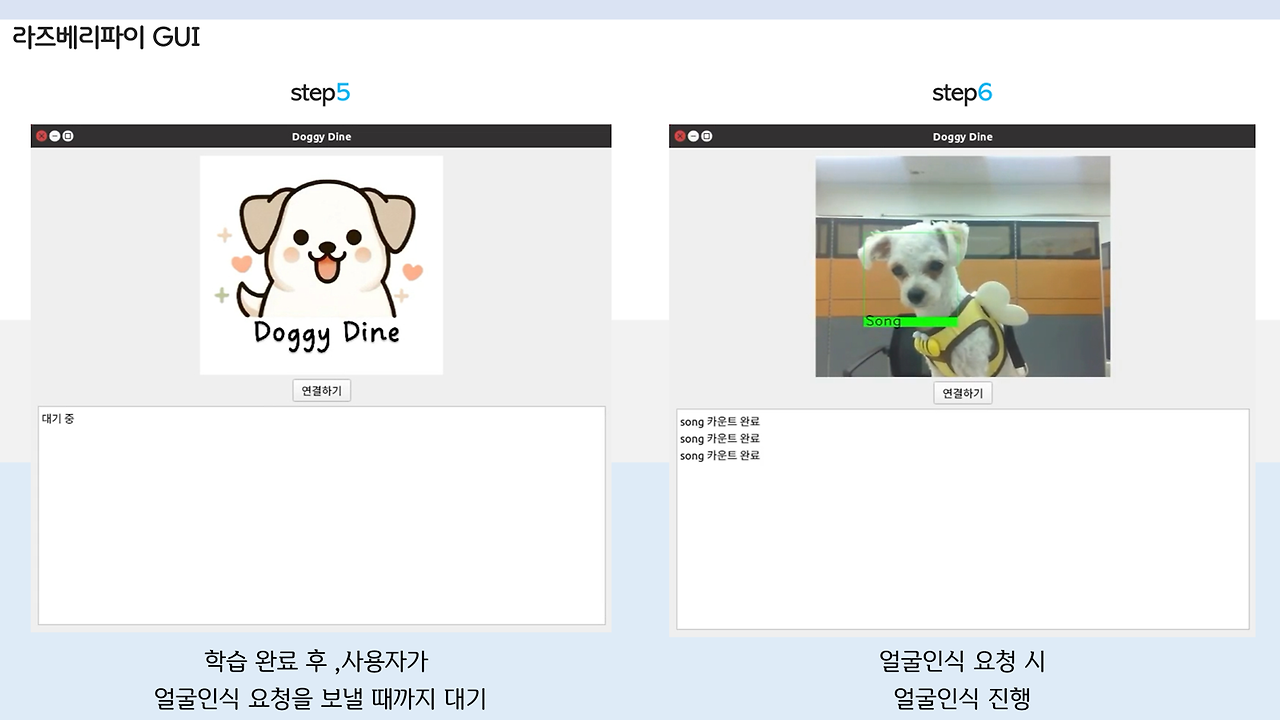
다음은 대망의...! 강아지 얼굴 인식 및 밥주는 부분입니다!!
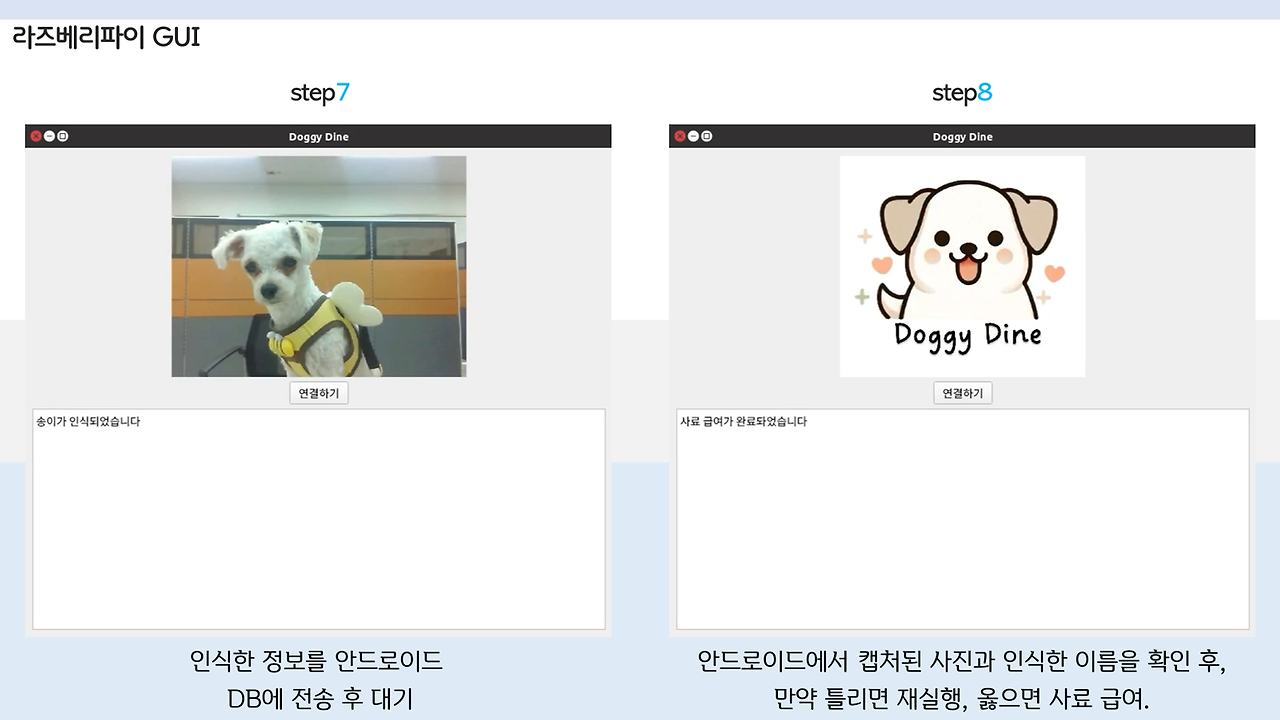
밥주기 버튼을 클릭하면 기기에서 카메라를 통해 앞에 있는 강아지의 얼굴을 인식하고, 그 결과를 사용자에게 알려주게 됩니다! 그리고, 인식된 강아지 이름을 바탕으로 데이터베이스에서 해당 강아지가 먹고 있는 사료의 칼로리, 강아지의 활동 수치 및 몸무게 등을 가져와서 종합적으로 고려해, 이번에 얼마의 사료를 줘야 하는지 계산합니다!!
여기서 만약 캡처된 사진과 인식된 이름이 다르다면 '다시하기' 버튼으로 인식을 다시 진행하도록 하였고, 만약 맞다면 급여하기 버튼을 통해 강아지가 밥을 얻을 수 있게 하였답니다.

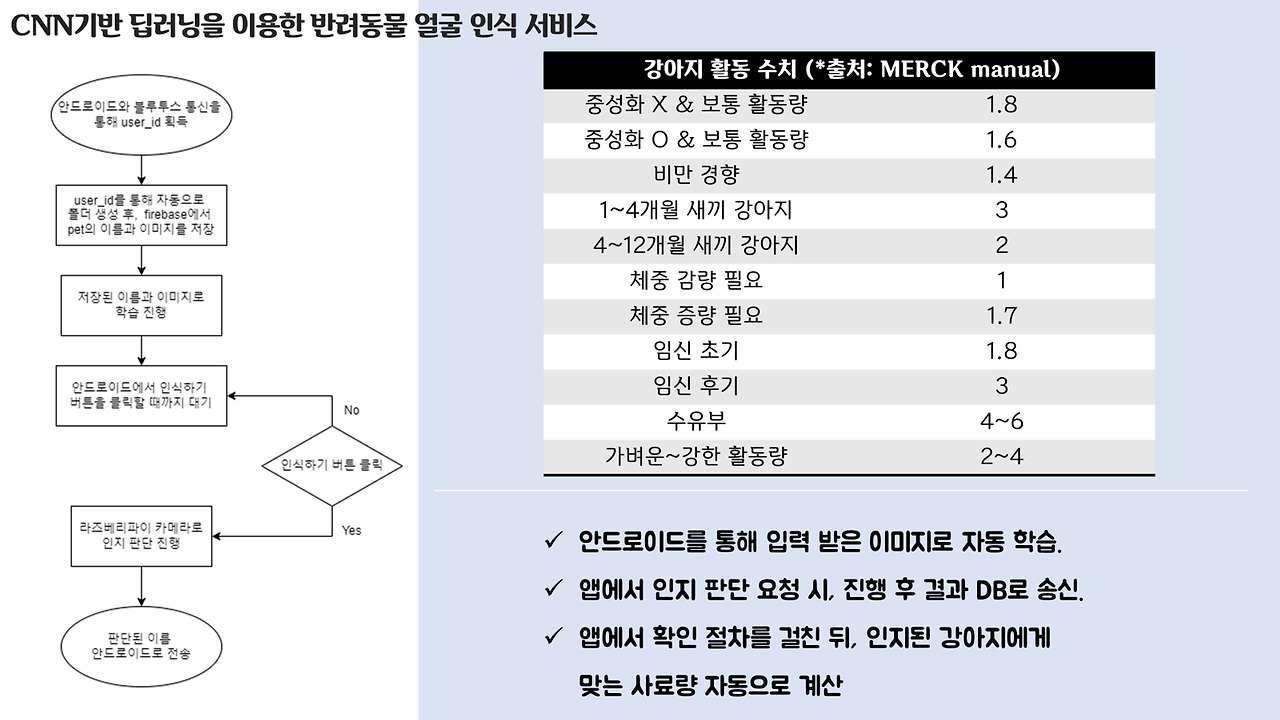
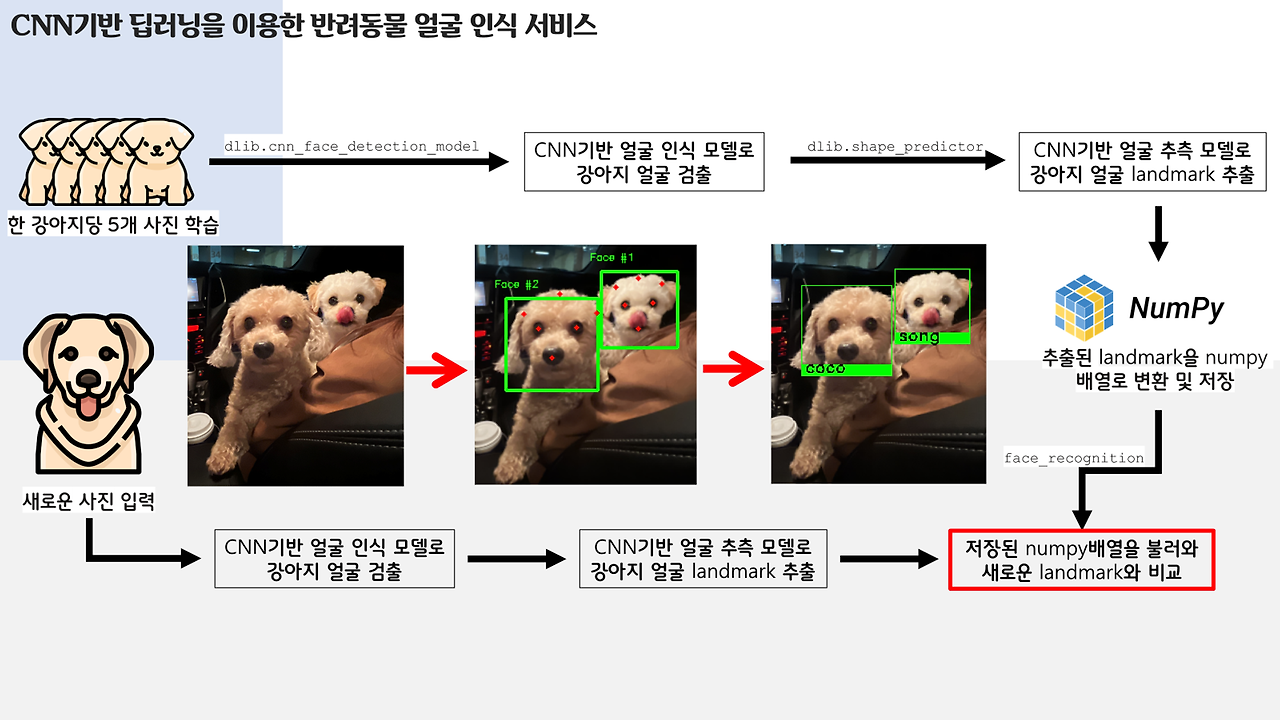

ㅎㅎ.. 제가 만든 프로세스 설명 및 얼굴 인식 딥러닝 자랑이에요.. 저 잘했죠..?
마지막 사진은.. 인스타 셀럽 찌나랑 빵지인데, 견주분께서 잠깐 발표에 사용하는 것은 괜찮지만 지속적으로는 사용 안해주셨으면 좋겠다고 하셔서 모자이크 해드렸습니다~ 왼쪽 강아지 두마리는 저희 집 강아지라서 초상권? 그딴거 없어요. ㅎㅎ
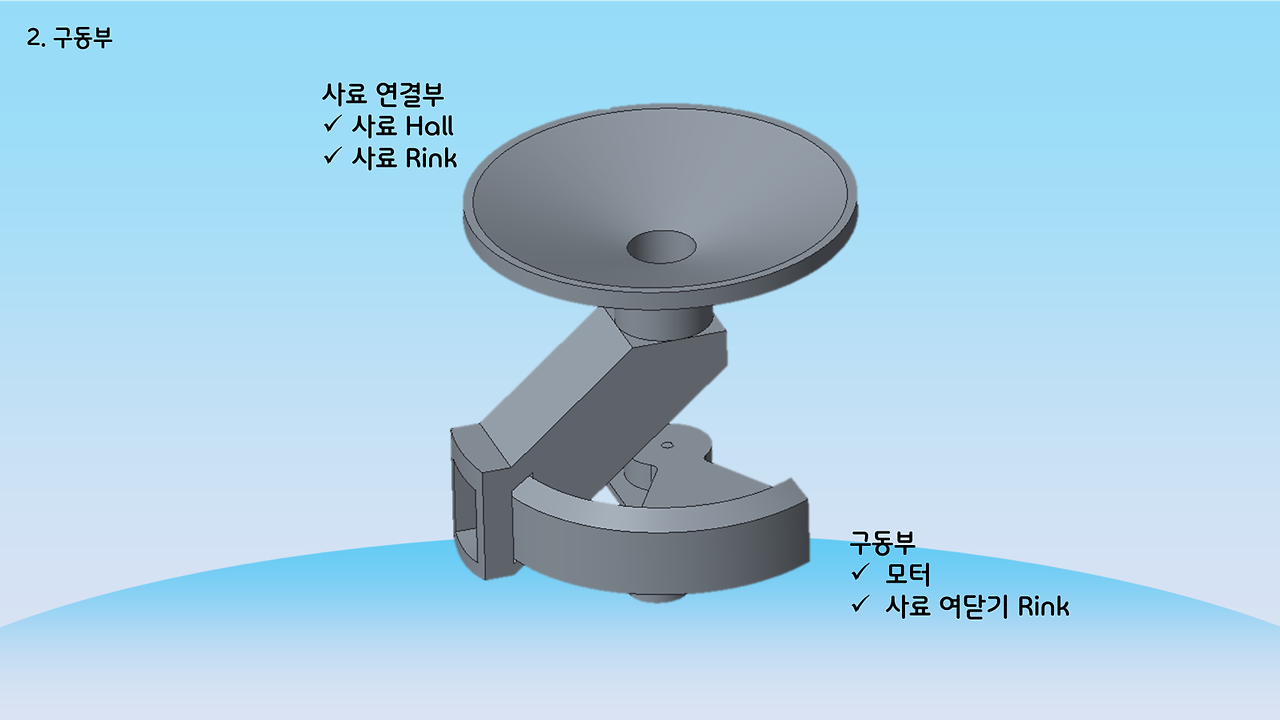
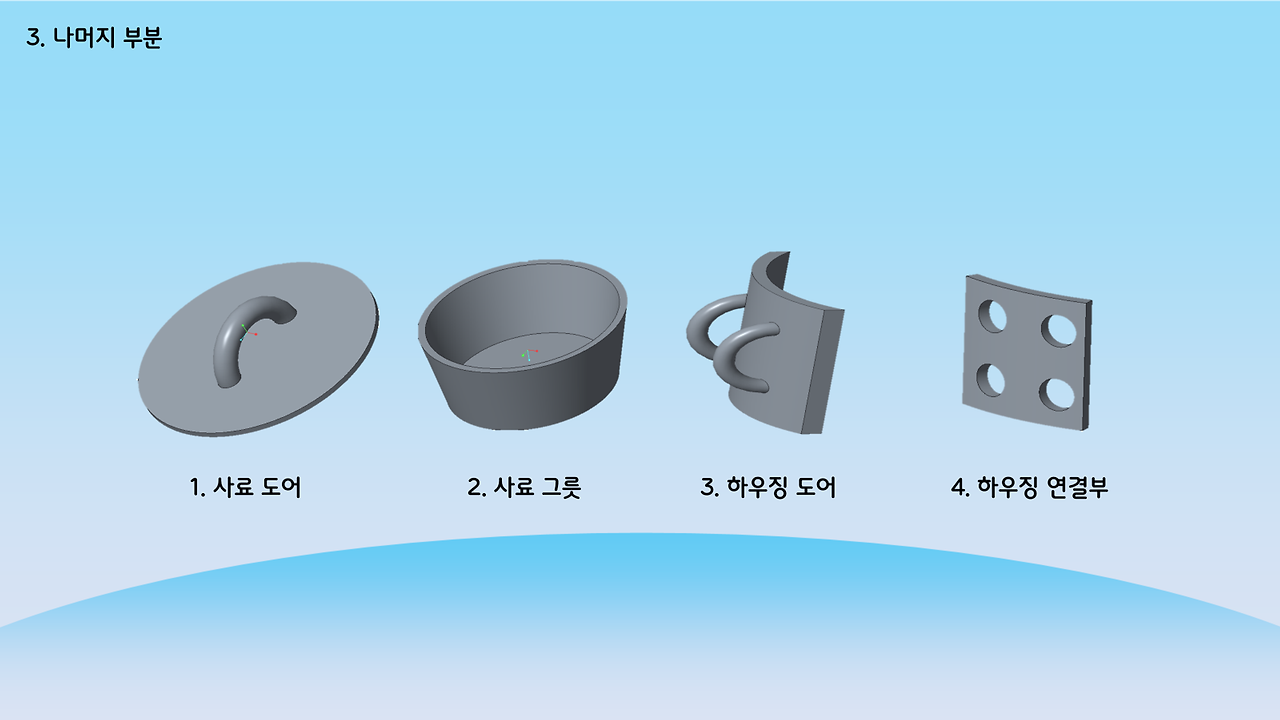
하드웨어
하드웨어 및 센서
다음은 하드웨어입니다. 사실, 앱이랑 딥러닝 부분을 제가, 데이터베이스와 관련된 모든 작업을 선배님께서 담당해주셨고, 나머지 한 친구는 앱을 다뤄본적도 AI를 다뤄본적도 없기 때문에 하드웨어를 맡게 되었습니다. 사실상 저희는 앉아서 컴퓨터만 뚱땅대면 됐지만, 이 친구는 그것도 아니라 제일 고생했죠.. 마지막에 제대로 되지 않은 부분이 하드웨어라 더 마음이 불편했을 겁니다. 3D 프린팅 한 부분은 온도가 안맞아서인지 우그러지고 센서는 계속 끊어지고.. 갑자기 라즈베리파이 안켜지고.. 회의 때도 저랑 선배님은 앱 개발 관련해서 계속 얘기하는데, 그 친구는 혼자 하드웨어하는 거라 회의때도 할 말도 없고 외로웠을 겁니다.. 암튼 고생했다..

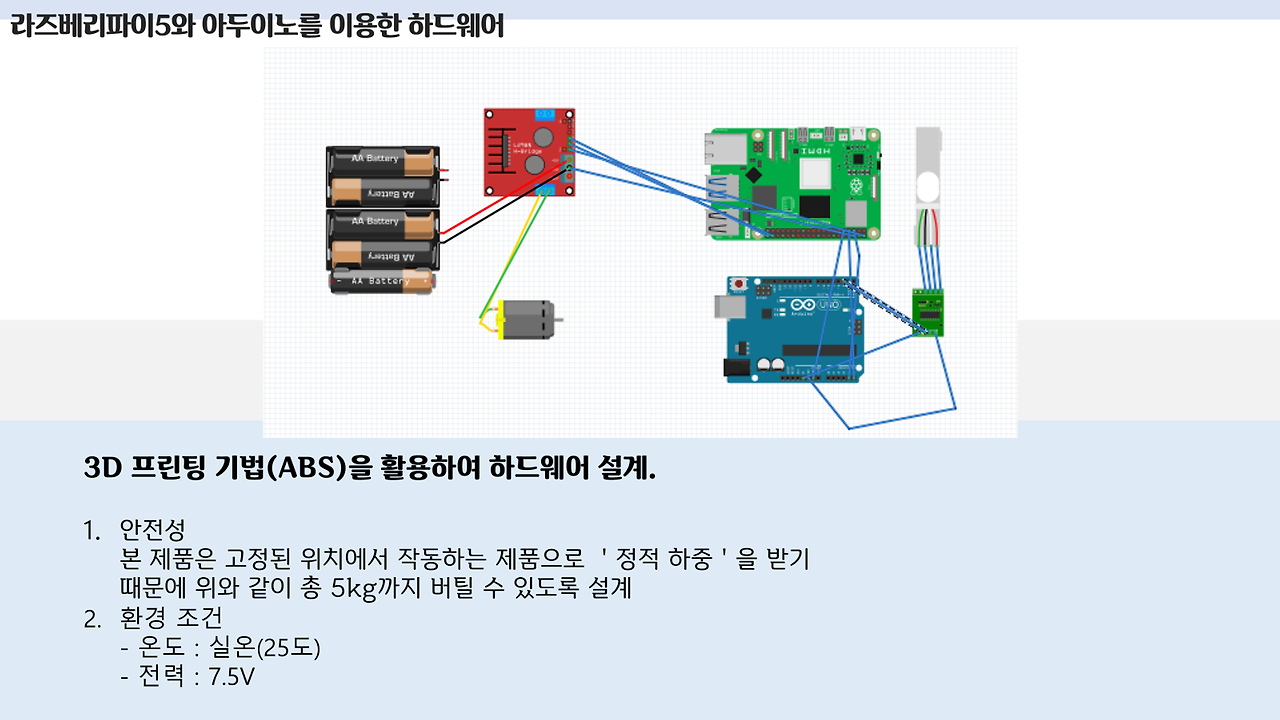

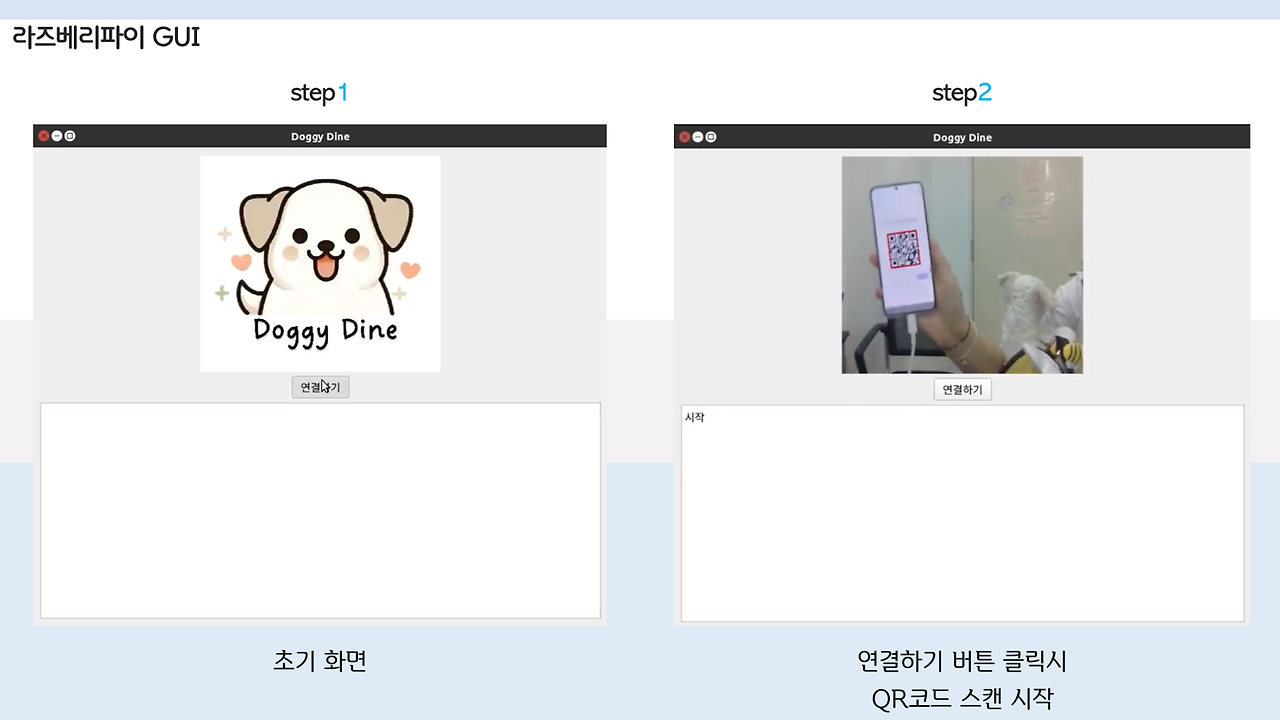
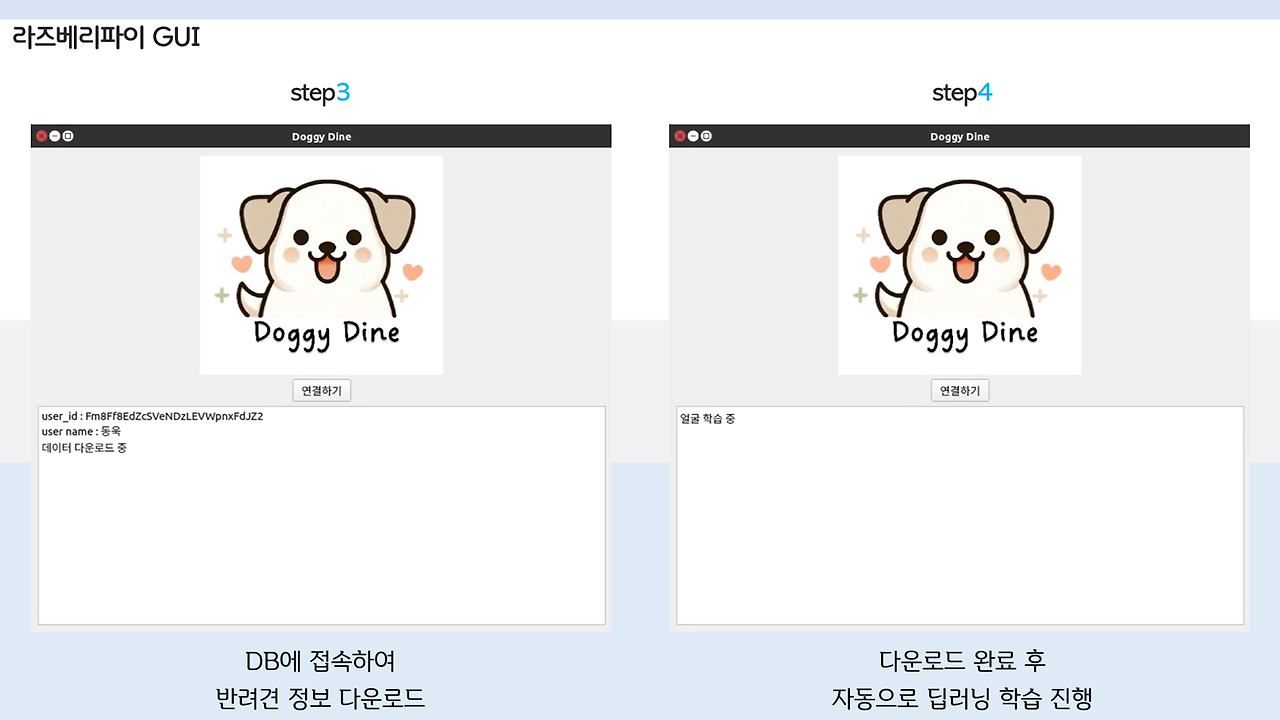
GUI for Raspberry Pi
GUI를 개발하는 부분은 앞의 포스팅에서 다뤘었습니당. 우리 송이.. 귀엽죠...?
사실 데모날 교수님 앞에서 멋있게 하려고 이쁜 한복까지 입고 갔었는데...
그냥 발표해야 되는데 강아지 데리고 온 사람이 되었습니다.. 속상..
사실 이 GUI는 시연영상을 만들기 위해 급하게 만들어진 아이로.. 아니, 원래 교수님 앞에서 보여드리면 이런거 필요 없거든요? 그래서 안만들었죠.. 근데 못했으니, 영상으로라도 성공해야 한다.. 라는 생각으로 급하게 만든거랍니다... 하...
그래서 좀 조잡하지만.. 첫 작품부터 잘 되기를 바라는 건 욕심이죠.. 다음에는 더 아름다운 GUI.. 만들어주마..
여기까지 제 졸업 프로젝트 소개였습니다!!
사실 저희끼리 저희 프로젝트 이렇게 부릅니다.
"다재다능 개쩌는 앱"
사실 맞는 말이죠.. 좀 기발하지 않나요? 온갖 기능 다 때려넣었답니다 하하하.
사실 이번 프로젝트에 제가 앱으로 할 수 있는 모든 걸 한 것 같아요.
누가 제게 '너 안드 얼마나 할 줄 알아?'라고 물어보면, 딱 여기까지 할 줄 안다고 말할 것 같습니다.
물론, 이후에 앱 개발자로 가게 되어서 더 다양한 툴도 써보고 한다면 얘기는 달라지겠지만,, 그러지는 않을 것 같습니다.
저 이제 졸업해요... 대학 4년 너무 길었다..
졸업 프로젝트를 끝내면서..
이제 한달 뒤 졸업생의 관점으로 제 대학시절을 돌아보자면.. 사실 너무 겁을 먹었던 것 같아요.
1-2학년을 좀 더 도전하면서 살았다면, 제 포스팅의 수준이 한 두단계는 높았을까요..?
이제와서 생각해보면, 혼자서 코딩 완벽하게 못하는 게 정상인데.. 취업 때문에 코딩 테스트 준비 하는 거 아닌 이상, 혼자 모든 걸 완벽하게 할 필요가 없었는데, 구글 도움도 좀 받고, 동기들이랑 의논도 좀 해야 되는게 맞는거였는데...
혼자 모든걸 완벽하게 했던 고등학교때를 계속 회상하면서, '아, 이것도 못하는 나는 코딩이 길이 아니구나, 나 못하는구나'라는 생각에 빠져있었습니다. 중간에 전과할까 진지하게 생각한 적도 많아요.
1학년 때, 코딩 동아리를 들어가기는 했지만, 알고리즘 스터디를 따라가기 벅찼고, 동기로부터 다른 코딩 동아리를 추천 받았지만, 앞에서 했던 동아리에서 제가 잘 못했기 때문에 '아, 내가 그걸 어떻게 해... 나 못해..' 하면서 그저 넘겼습니다.
2학년 때, 지금 하는 프로젝트들 홈페이지 만들어서 포트폴리오로 정리하라고 말을 들었을 때, '나 코딩도 못해, 웹 개발 배운적도 없어. 그걸 내가 어떻게 해..' 하면서 그저 흘렸습니다. 근데, 지금 아무한테도 안배웠지만 혼자 만들었죠...
2학년 마지막에는 유니스트 연구원으로부터 앱 개발 협업 제안까지 왔었지만, 나는 못한다는 생각에 사로잡혀서 그저 기회를 보내버렸어요.
내가 뭘 좀 모르더라도, 못하더라도, 일단 도전하고 계속 공부하면서 치열하게 싸워왔다면, 저는 지금이랑 좀 다른 사람이었을 거라는 생각이 듭니다. 어쨌던 저는 학생이었고, 학생은 계속 배우는 사람인거니까요.
앞으로는 좀 더 배우고, 도전하는 사람이 되고 싶습니다. 많이 응원해주세요😉
'정보통신공학전공 > 캡스톤 디자인' 카테고리의 다른 글
| [Python] GUI 만들기 (0) | 2024.07.07 |
|---|---|
| [Python] 강아지 얼굴 인식하고 구분하기 - 2 (0) | 2024.04.16 |
| [Python] 강아지 얼굴 인식하고 구분하기 - 1 (1) | 2024.04.07 |
| [Java]Android Studio에서 AI 챗봇 만들기 (1) | 2024.03.28 |
| [Python] Openai로 AI챗봇 만들기 (0) | 2024.03.28 |